Ever come across a website overflowing with stunning visuals you’d love to use in your project? This technique allows you to scrape website for images, opening a treasure trove of visual content for your needs.
In this comprehensive blog, we’ll delve into the world of image scraping. We’ll explore how to leverage Python for this task, unveil alternative methods like no-code tools to scrape images from website, and equip you with best practices for ethical and legal image scraping. So, get ready to unlock the power of website images and incorporate them into your projects seamlessly!
What Is Image Scraping?
Image scraping takes web scraping to the visual level, allowing you to extract images (JPEGs, PNGs, GIFs) from websites. Unlike manual copying and pasting, this technique often involves automation. You can achieve this through:
- Python libraries: Code libraries like Beautiful Soup empower you to write scripts that automatically find and extract images based on specific criteria.
- No-code scrapers: These user-friendly tools offer a drag-and-drop interface, making image scraping accessible even without programming knowledge.
Is It Legal to Scrape Website for Images?
Whether it’s legal to scrape website for images depends on several factors:
- Website’s Terms of Service (TOS): Every website has a TOS outlining acceptable user behavior. Scraping might be explicitly prohibited in some cases. Always check the TOS before scraping images from a website.
- Robots.txt: Many websites use robots.txt files to communicate with scraping bots. Respecting these guidelines demonstrates good internet citizenship and avoids violating website rules.
- Copyright Laws: Generally, scraping publicly available images is considered acceptable. However, be cautious about scraping copyrighted images without permission. If the image creator doesn’t explicitly allow scraping or charges a fee for use, it’s best to avoid it.
Here are some additional ethical scraping practices to keep in mind:
- Scrape responsibly: Avoid overwhelming a website with excessive scraping requests. Use tools that implement throttling to mimic human browsing behavior.
- Respect robots.txt limitations: If a website’s robots.txt disallows scraping, don’t bypass it.
- Focus on publicly available data: Avoid scraping private or sensitive images.
How to Scrape Website Images with Python

This comprehensive guide empowers you to scrape images from websites using Python. Here’s a step-by-step guide to scrape website for images using Python:
Choosing Your Weapon: Library Installation
The first step is to equip yourself with the right tools. The choice of library depends on the complexity of your scraping task. Here’s a breakdown of popular options:
- Beautiful Soup & Requests: Ideal for beginners, these libraries offer a simple approach for basic scraping needs. Beautiful Soup helps parse the HTML content, while Requests facilitates sending requests to web pages.
- Scrapy & Pillow: For more advanced tasks, consider Scrapy and Pillow. Scrapy provides a robust framework for large-scale scraping projects, while Pillow assists with image manipulation tasks.
- Selenium: This library shines when dealing with dynamic web pages that require user interaction, like clicking buttons or navigating menus.
Installation is a breeze using the pip command (Python package installer). For example, to install Requests, type pip install requests in your terminal.
Scouting the Target: Identifying Image URLs
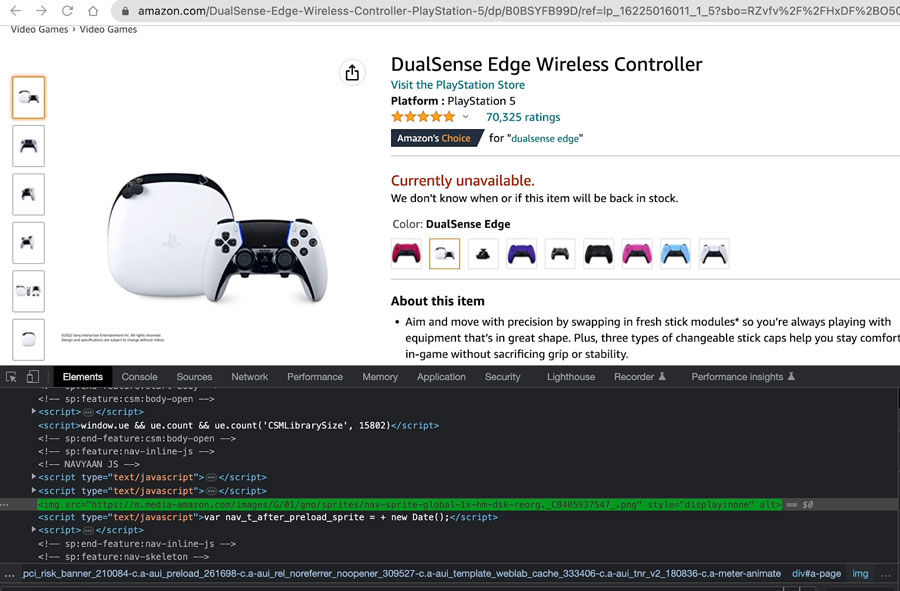
Before you download, you need to know where to find the images. Open your target web page and use your browser’s developer tools to inspect the HTML source code. Look for <img> tags, which typically contain the image URL in the src attribute (see Figure 1). Copy the URL for later use in your Python script.
Sending the Signal: Requesting the Webpage
Once you have the target URLs, it’s time to retrieve the web page itself. Libraries like Requests allow you to send a request to the webpage containing the images you want to scrape. Here’s an example using Requests to scrape an image from an Amazon product page:
Python
url = ‘https://amazon.com/xyz’
response = requests.get(url)
Decoding the Message: Parsing the HTML Content
The response from the web page will be in HTML format. To make sense of it, we need to parse the content. Libraries like Beautiful Soup or lxml come to the rescue. They help break down the HTML structure into easily readable elements.
Extracting the Treasure: Finding Image URLs
Now comes the exciting part – finding the image URLs. With Beautiful Soup, you can iterate through all the <img> tags and extract the relevant image URLs from the src attribute. This allows you to create a list of URLs for all the images you want to download.
Downloading the Booty: Saving the Images
With the image URLs in hand, it’s time to download the actual images. Python offers several options:
- urllib: This built-in library provides the urlretrieve() function to download files from a URL.
- urllib2: While less commonly used, it offers advanced functionalities for HTTP requests. You can use urlopen() to open a connection and read() to retrieve the image data.
- Requests: This popular library shines again. The get() function sends a request to the URL, and the content attribute holds the downloaded image data.
Securing the Loot: Saving the Downloaded Images
The final step is to save the downloaded image data to your local storage. The os module provides functions for file manipulation. You can specify a directory path and filename to save the image data using appropriate file extensions like .jpg or .png.
Read more: How To Scrape Data From A Website
Online Tools to Scrape Images on Websites
There are online webpage tools that let you download images directly from a website, all without any installation required. These tools work seamlessly with most browsers, so you can grab those images regardless of which one you prefer.
Image Cyborg
Image Cyborg entices users with its lightning-fast download of all images on a webpage. It boasts a search-engine-like interface – simple and straightforward, with the sole purpose of image grabbing.
However, while user-friendly, there are some limitations to consider based on my experience:
- Resolution Regret: Beware of low-resolution downloads. Most captured images tend to be thumbnails, meaning they might not be suitable for high-quality use.
- Zipping Woes: Get ready for repetitive renaming. All downloaded images are compressed into a single zip file named “[image-cyborg]”. You’ll need to rename each image file individually.
- Logo Limbo: While Image Cyborg captures various images, it might miss logos or avatar images you might find essential.
Extract.pics
Extract.pics stands out among image scraper tools with its user-friendly interface. It offers a clear and uncluttered layout, making it easy to navigate. But the real star of the show is the preview function. Before downloading, you can see thumbnails of all the images on a webpage, allowing you to select or deselect them individually. This is a great way to ensure you’re grabbing only the images you need.
However, there’s a potential hurdle to be aware of. Downloading all images with a single click might not always work as expected. You might encounter an error message when attempting this bulk download. So, while extract.pics offers a great preview feature, be prepared to download your desired images one by one if the “download all” function gives you trouble.
Using Browser Extension to Scrape Images
Besides the tools we mentioned, you can use Browser Extension to scrape website for images.
Firefox
There’s a hidden gem in Firefox that lets you download all the images on a website with just a few clicks! It might surprise you how easy it is.
Here’s how to do it:
- Open the website with the images you want to download in Firefox.
- Right-click anywhere on the blank area of the webpage.
- From the menu that appears, select “View Page Info.”
- In the Page Info window, navigate to the “Media” tab. This tab displays a list of all the images embedded on the webpage.
- Click “Select All” to highlight all the image URLs.
- Finally, click the “Save As” button to download all the selected images to your desired location.
Keep in mind: This method has a limitation. Images saved through the “Media” tab might not be downloaded in their original web format (e.g., .webp). They might be saved in a more common format like .jpg or .png.
Chrome or Edge
For Chrome users, scraping images from websites becomes a breeze with image downloader extensions. These handy tools eliminate the need for complex methods.
Here’s how it works:
- Navigate to the website containing the images you want to download using your Chrome browser.
- Locate the image downloader extension icon in the top-right corner of your Chrome window. It’s typically represented by a white arrow on a blue background.
- Click on the icon to launch the extension. This will display a pop-up window showcasing all the downloadable images found on the current webpage.
- Many image downloader extensions offer a filtering option. This allows you to refine your selection by excluding tiny icons and focusing solely on downloading the standard-sized images you need.
With this simple process, you can efficiently download the desired images from websites using Chrome extensions.
Using No-coding method
No-code image scrapers are game-changers for anyone who wants to extract images from websites without coding. Instead of writing complex scripts, these tools offer a user-friendly graphical interface (GUI). Think of it as a point-and-click system – you simply navigate to the webpage and select the images you want to save.
But are no-code options always the best fit? It depends on the complexity of your task. For smaller scraping needs, no-code tools are perfect. However, some offer additional features that can be helpful for larger projects. For instance, some no-code scrapers include:
Proxy servers: These act as intermediaries when sending requests to websites, potentially helping you bypass restrictions.
Anti-scraping solutions (e.g., CAPTCHA solving): Some websites use CAPTCHAs (those distorted text puzzles) to prevent automated scraping. No-code tools with built-in solutions can help you overcome these hurdles.
How to Avoid Common Challenges
Image scraping can be a valuable tool for gathering visual data, but it’s crucial to approach it cautiously and ethically. Here are some key best practices to avoid common challenges when you scrape website for images:
Know Your Image Formats and Sizes:
The world of web images is a diverse one. Images come in various formats like JPEG, PNG, GIF, and even newer formats like WEBP. They also range in size, from tiny thumbnails to large, high-resolution photos. Ensure your chosen image scraper can handle this variety. Some tools might only capture specific formats or prioritize larger images, potentially missing valuable data.
Respect the Law and Be Ethical:
Copyright laws are in place to protect the intellectual property of creators. Scraping images in violation of these laws can land you in hot water. Before scraping images from any website, take the time to review their terms of service and the Robots.txt file (a file that tells search engines and bots which parts of a website they should not crawl). These resources will outline the website’s scraping policies and any restrictions they might have.
Don’t Overload the Server:
Websites have limited resources, and excessive scraping requests can overload their servers. Be mindful of the frequency and volume of your requests. Here are some ways to be a responsible scraper:
- Rate Limiting: Many websites implement rate limits to control the amount of data crawlers can access within a specific timeframe. Respect these limits and adjust your scraping frequency accordingly.
- Time Delays: Adding short time delays between your requests gives the website’s server time to breathe and prevents overloading.
- Caching: Caching downloaded images locally helps avoid requesting the same image data repeatedly, reducing the strain on the server.
Be Transparent and Accountable:
If you intend to use scraped images commercially or publicly, it’s best practice to be transparent about your scraping activities. In some cases, it might be appropriate to reach out to the website owner and seek permission to scrape images from website online.
By following these best practices, you can ensure your image scraping activities are ethical, legal, and respectful of the websites you target. Remember, responsible scraping benefits everyone – you get the data you need, and the websites you scrape from maintain a healthy online presence.
Read more:






