
Imagine the web as a vast, vast library, whispering secrets. Scrape all Links from a Website as the key to unlocking those secrets, a tool that gives you insights to outpace your competitors and change the way you work. With billions of vibrant websites, the digital landscape is a torrent of information. But how do you harness this unstoppable flow?
The vastness of the site is a double-edged sword. Sure, the data is there, but sifting through it manually would be an impossible task. To turn this chaos into clarity, you need the right tools. You can write your own web scraper, flex your coding skills, or take advantage of the power of the built-in web scraping API. APIs streamline the process, trading hours of coding for a solution that gets you the data you need quickly.
So, what treasure is hidden in the URL list? The answer depends on your mission. Market trends, product comparisons, and even whispers about your brand are all waiting to be discovered. This article is your map. We’ll guide on you how to scrape all links from a website, answering all the questions that may arise along your journey. If you know the basics, our table of contents will get you straight to the heart of advanced techniques.
Enough talk, adventurer! It’s time to sharpen your tools and get started. Let’s make those URLs yield hidden knowledge!
What Is HTML Website Scraping?
The Internet is not just a spectacle that you see but also a symphony of codes. Every website you visit has invisible instructions and lines of code that the developer has carefully created. A scroll bar appears, and a button flashes – it’s the language of the website whispering a hidden song.

Some people believe that the heart of this code is HTML (Hypertext Markup Language). It’s a language of structure, a set of simple commands that even a curious novice can begin to understand. That’s why HTML holds a special place in the field of self-taught programmers who aren’t afraid to sneak a peek.
But inside this code lies hidden treasure! The right tools can reveal the secrets contained in HTML, like precious gems waiting to be found. Imagine retrieving valuable data and storing it for your own purposes. This is the power of HTML scanning, giving you access to:
- Metadata: Information about information maps inside the code.
- Page properties: Characteristics of the website, such as its size and structure.
- Alt text: Description for those who can’t see the image, a bit of accessibility.
- URL: Links to other treasures, pathways to deeper discovery.
Why Do You Need to Scrape All Links from a Website?

URLs are the thread that binds websites together. They’re a treasure map for the daring, leading to research gold, new website designs, and even the secrets of your competitors. Sure, you can scrape all links from a website by hand with a quick copy and paste… but the web scraper is like a tireless explorer, unearthing more links than you can find alone.
Think of all the things URLs can do for both businesses and curious explorers. The treasure lies here:
- SEO investigation: Imagine there are hundreds of competitor websites, each revealing their keyword secrets. Take their URL, analyze their hidden words, and your site will rise higher in search results.
- Build a magical website: Your own website, an aggregator that collects the best content from all over the internet! But those links change faster than the tides – only the tireless scraper can keep it fresh.
- Real estate prophet: Property values dance like flames. Scan URLs and follow listings, and you’ll know the true value of land, whether you’re buying or selling.
- Know your enemy: Your competitors’ websites reflect your business. Scan their URLs, study their moves, and YOUR strategy becomes unstoppable.
What Are the Challenges of Website Scraping?
When scraping large amounts of data quickly, you risk being flagged by anti-scraping measures that websites have in place to protect their content. Website administrators may not distinguish between well-intentioned and malicious data extraction, so they’ll often take steps to stop automated bots when detected.
Here are some specific challenges you might face while web scraping:
- CAPTCHAS: These puzzles, designed to distinguish humans from computers, are meant to thwart automated scraping activities.
- Honeypot traps: These hidden links, invisible to human users, will be readily detected by your scraping bot. Clicking on such a link instantly reveals the bot’s automated nature.
- IP Blocking: Website administrators might issue warnings if they notice unusual activity from an IP address. Continued suspicious behavior can lead to a complete block, stopping your scraping efforts.
- Dynamic content: While intended to improve user experience, dynamic content (often loaded using JavaScript or similar technologies) can be difficult for scraping bots to handle, slowing down the extraction process.
- Login requirements: Sensitive data on some websites is password-protected. Repeated attempts by your bot to access these areas could trigger security systems and lead to a ban.
Read more: How to Scrape Website With Login?

5 Steps to Scrape All Links from a Website
While theoretically possible, manually extracting URLs from websites is a painstaking process. Depending on how many URLs you need, it can be incredibly time-consuming and inefficient. This method involves sifting through code to find specific tags – a task often compared to finding a needle in a haystack.
For larger-scale data extraction, you have two main choices: buy a web scraping tool or build your own. Building a tool offers customization but might be time-consuming or costly if you need to hire a developer. Ready-to-use solutions often remove this hassle. Web scraper APIs can quickly pinpoint the URLs you want, as well as extract and organize them into your desired format.
To extract URLs from websites, follow these steps:
- Choose an HTML web scraper: Many options exist, such as Scraping Robot, which offers a user-friendly HTML API to extract various elements from a website’s code, including URLs.
- Select the right module: Reputable scraping tools offer multiple modules for tailored extractions. You might use a search engine module to pull top-ranking URLs for a keyword.
- Configure your project: Follow the module’s instructions, providE any necessary input, and set parameters for the data you want. Give your project a descriptive name.
- Extract the URLs: Run the API and let the tool collect the information. When finished, view the results in your chosen output file format.
- Repeat as needed: Run this process repeatedly to gather all the URL data you need over time.
How to Scrape all Links from a Website?
Below are three effective ways you can use to scrape links from website. Come learn with me and choose the method that best suits your needs and your business.
URL Scraping Tools
One of the methods to help you scrape all links from a website quickly and effectively that I want to mention is the URL scraping tool, a typical example of which is RPA Cloud.
RPA CLOUD is a cloud-based work automation software solution that makes it easy for users to get work done quickly and efficiently.
Friendly interface: RPA CLOUD has an intuitive, easy-to-use interface, helping users of all levels to simply automate tasks.
Diverse automation: RPA CLOUD not only helps automate repetitive tasks but also provides web scraping services to business owners and enterprises.
Salient features:
Get data: Get the inner text or HTML of all elements that match the CSS selector.
Extract data: Extract data from a complex table located on the website.
Information processing: Processing extracted information to serve different purposes.
Good price:
- Free trial without providing credit card information.
- Standard plan: $15 per month
- Premium plan: $30 per month
- Enterprise plan: $50 per month
- Cooperation plan with unlimited service.
Visit RPA CLOUD’s website for more detailed information and free experiences!
JavaScript
Need to quickly grab all the URLs from a webpage? Here’s a handy JavaScript snippet to do that directly in Google Chrome Developer Tools – no extensions needed!
This code will extract a CSV-formatted list of all the URLs on the page. Each entry will include the link’s anchor text and indicate whether the link points to another page within the same website (internal) or to a different website (external).
Once you have your list, simply copy and paste it into your favorite spreadsheet program, like Google Sheets. Alternatively, you can use a specialized tool like the Datablist CSV editor for further manipulation and analysis.
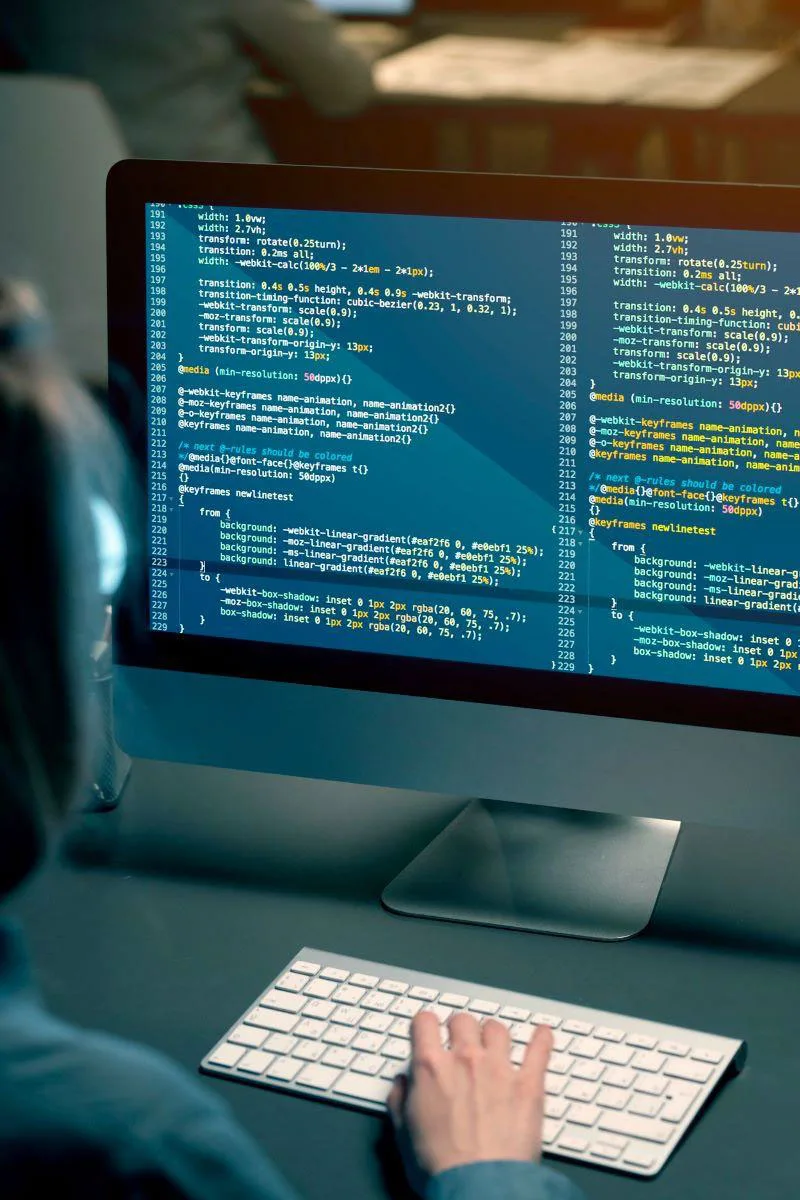
Run JavaScript code in Google Chrome Developer Tools:
To execute JavaScript code within your web browser, you’ll need to access the Google Chrome Developer Tools. Here’s how to open them:
Mac: Press Cmd + Opt + i
Windows: Press F12
Once the Developer Tools window is open, locate the “Console” tab and click on it. This is where you’ll paste the provided JavaScript code. When you’re ready to run the code, simply press the “Enter” key.
const results = [
[‘Url’, ‘Anchor Text’, ‘External’]
];
var urls = document.getElementsByTagName(‘a’);
for (urlIndex in urls) {
const url = urls[urlIndex]
const externalLink = url.host !== window.location.host
if(url.href && url.href.indexOf(‘://’)!==-1) results.push([url.href, url.text, externalLink]) // url.rel
}
const csvContent = results.map((line)=>{
return line.map((cell)=>{
if(typeof(cell)===’boolean’) return cell ? ‘TRUE’: ‘FALSE’
if(!cell) return ”
let value = cell.replace(/[\f\n\v]*\n\s*/g, “\n”).replace(/[\t\f ]+/g, ‘ ‘);
value = value.replace(/\t/g, ‘ ‘).trim();
return `”${value}”`
}).join(‘\t’)
}).join(“\n”);
console.log(csvContent)
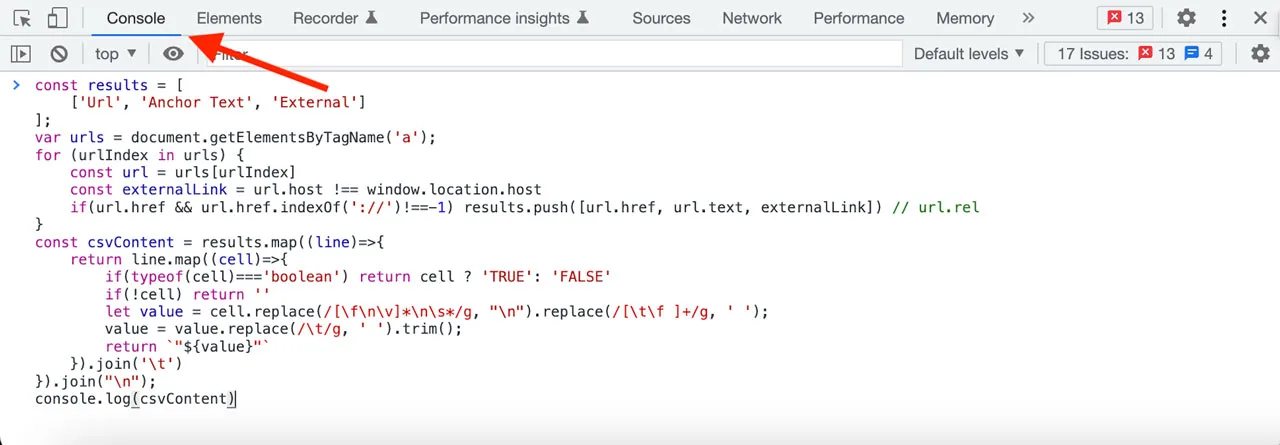
Copy-paste exported URLs into a CSV file:
The JavaScript code will find all the links on the webpage and provide you with the following information:
- URL: The actual address of the link.
- Anchor Text: The words or phrases that are visible and clickable for the link.
- External: This tells you whether the link goes to another page on the same website (FALSE) or a different website entirely (TRUE).
The code will output the list of links in a CSV format directly in your browser’s console. You have a few options to work with this data:
- Copy and Paste: Directly copy and paste the results into your preferred spreadsheet program (like Google Sheets or Microsoft Excel).
- CSV Editor: Use a specialized online tool, like the mentioned Datablist CSV editor, for more advanced editing.
- Save as a .csv file: Create a basic text file, paste in the results, and save it with the “.csv” extension.
If the code extracts a large number of links, Google will automatically add a “Copy” button within the console, making it even easier to transfer your results.
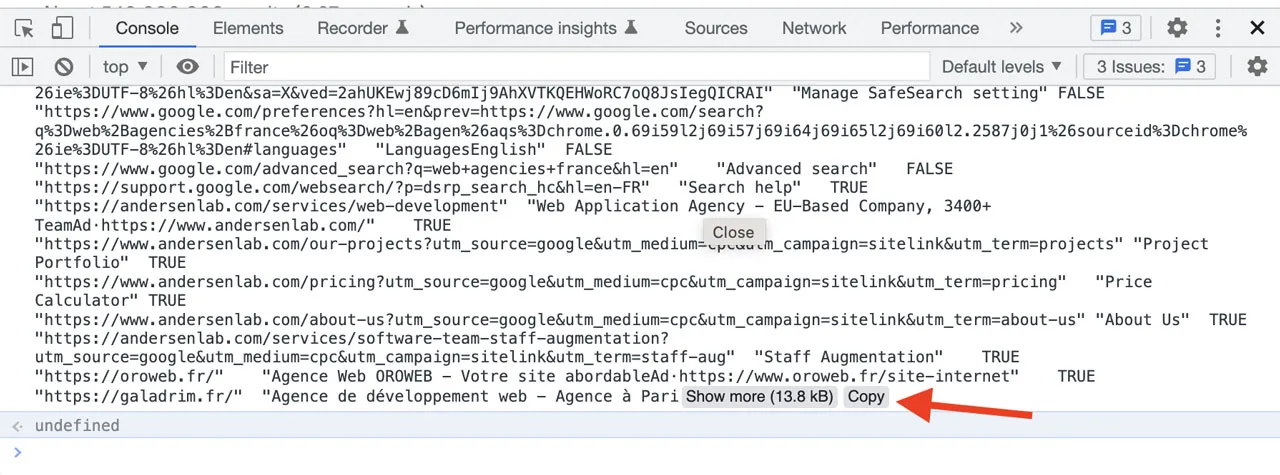
Filter CSV data to get links:
If you need to filter and refine your extracted URL list, the Datablist CSV editor provides a user-friendly solution. Start by creating a new collection within Datablist and paste your CSV data. Ensure that the “First row contains header” option is selected, and click the “+” button to import each column. (If you’d like more detailed instructions, check out the provided Google and Amazon examples).
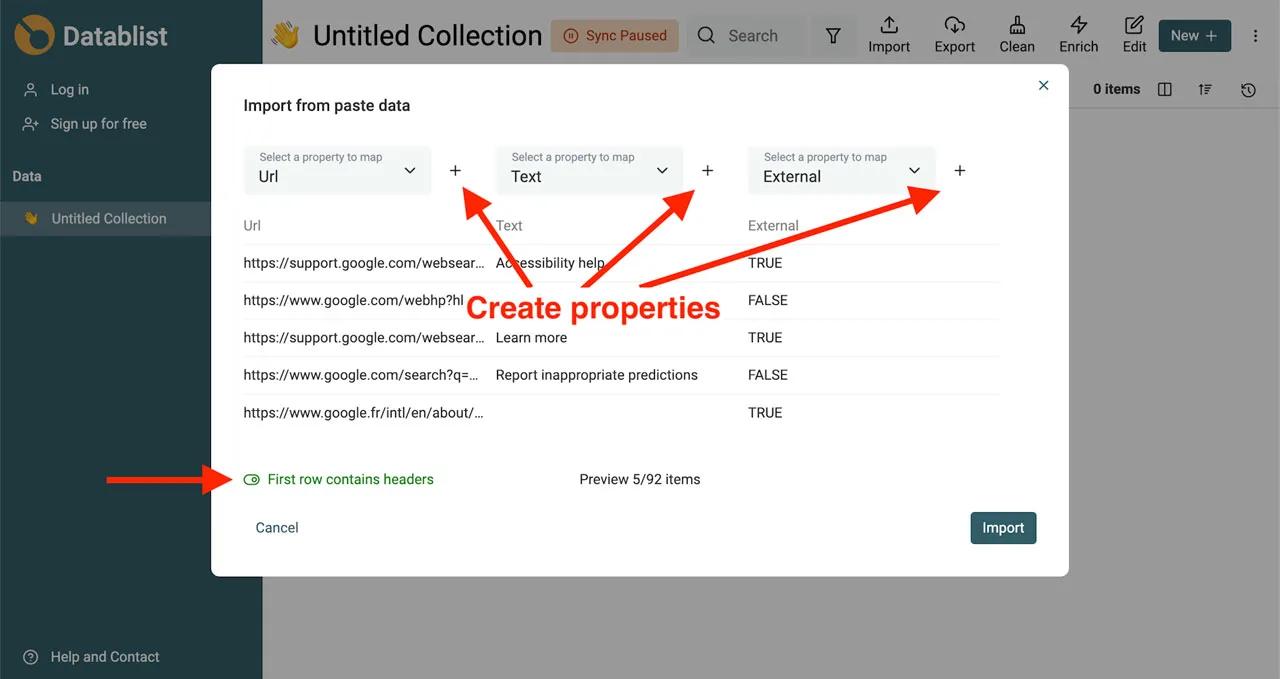
Once your data is imported, you have powerful filtering options at your disposal. Search for links containing specific text or filters based on properties like the “External” column (to separate internal and external links). Datablist is a great tool for managing and consolidating all your CSV data in one place. Best of all, it includes a deduplication algorithm to automatically remove any duplicate URLs, ensuring a clean and accurate list.
Browser Extensions
To scrape all links from a website, you can use Google Chrome Extensions, such as Link Klipper:
Simplify the way you collect links with Link Klipper! This powerful Chrome extension lets you extract all links from any webpage and neatly export them into a CSV file. No more time wasted copying and pasting links one by one.
Link Klipper offers these convenient features:
- Extract all links: Capture every link on a webpage in seconds.
- CSV export: Organize your links in a spreadsheet-compatible format.
- Custom selection: Drag a box on the page to extract links only from a specific area.
Using Link Klipper is simple. Just right-click anywhere on a webpage and find the “Link Klipper – Extract Links” option in the menu.
Link Klipper is perfect for various tasks:
- SEO Professionals: Quickly gather links for analysis.
- Image Browsing: Download the target links of images on any webpage.
- Researchers: Collect and store valuable links in a CSV file for later reference.
While the basic techniques to scrape all links from a website can handle simple tasks, they may not be the best fit for large-scale projects or complex business analysis. That’s where a dedicated data delivery service excels. Our company specializes in scraping and processing information for clients, saving you significant time and effort.
By outsourcing your data extraction, you gain several advantages. We ensure the highest data quality by carefully targeting the right URLs, verifying relevance, and meticulously cleaning the results. This delivers immediately usable data, allowing you to focus directly on analysis and insights.
Read more:






