
Web Scrape Multiple Pages involves extracting data from multiple web pages using automated techniques. It will be difficult at first, but using user-friendly libraries like Beautiful Soup will greatly simplify the process. Beautiful Soup is a Python library created for web scraping. It becomes one of the perfect tools for both beginners and experienced developers.
Data plays an extremely important role in our lives and in every business decision. This valuable information can be extracted and used for a variety of purposes, such as product research, market analysis, and project development.
Although manually copying and pasting data seems like a simple approach, it is very time consuming. It becomes impractical when you need to process large volumes of information. That’s why web scraping has emerged as a great solution to help businesses collect and process large amounts of data from the web.
Before embarking on any web scraping effort, it is important to adhere to ethical principles to ensure legal and respectful data collection practices:
- Seek permission: Whenever possible, ask the site owner for explicit permission before removing their content.
- Comply with Terms of Service: Carefully review your site’s Terms of Service (ToS) and robots.txt file to understand any restrictions or limitations on data collection.
Respect bandwidth: Pay attention to your website’s bandwidth usage and avoid overloading its servers with excessive crawl requests. - Use the right tools: Use web scraping tools that respect site ownership and comply with ToS and robots.txt guidelines.
Before we start coding, one of the important things is to understand how web scraping works. Now you know the basics of the Chrome web scraper multiple pages. Practice with Python and BeautifulSoup, a super easy-to-use web scraping library, to get the best look at this.
In this blog post, we will break down the content so you can understand it clearly and best. First, we will discuss collecting data from a website. Once you’ve mastered that, we’ll expand our skills and learn how to crawl across multiple sites.
What Are the Required Factors for Web Scrape Multiple Pages?
To start this exciting web scraping journey, prepare some necessary tools:
- Python 3: This tutorial uses the Python library, so you need to install Python 3. Visit the official Python website to download and install the appropriate version: https://www.python.org/downloads/
- Beautiful Soup: Beautiful Soup is a powerful Python tool for parsing structured data, especially useful for extracting information from HTML. It creates an analysis tree that makes it easy to navigate and collect the desired data.
- Install Beautiful Soup: pip install beautifulsoup4
- Requests Library: The Requests library is the standard library in Python for making HTTP requests. It plays an important role in accessing and retrieving the HTML content of the target website.
- Requests settings: pip install requests
- lxml parser: To extract data from HTML text effectively, we use a parser. Our choice in this tutorial is the lxml parser.
- Install lxml: pip install lxml
Note: Don’t worry if you don’t have in-depth knowledge of Python. This tutorial is designed to be easy to follow for all levels.
By installing all the necessary tools, you are ready to embark on a journey to explore and collect information from the vast web with Beautiful Soup and Python.
How to Scrape a Single Web Page?
Remember, we’re starting with the basics – learning how to scrape data from just one web page. Once you’ve got that down, we’ll level up and tackle scraping information from multiple pages.
Ready to get this show on the road? Let’s dive into building your very first web scraper!
Import the Libraries
Before we start scraping, import the libraries :
Python
import requests
from bs4 import BeautifulSoupGet the HTML
We’re going to tackle a website with tons of movie transcripts. Let’s start with just one page to get the hang of it; then we’ll scale up! For this example, we’ll use the Titanic transcript, but feel free to pick your own favorite.
Here’s the breakdown of what we’ll do:
- Connect to the Website: We pinpoint the specific page we want to scrape (here, it’s the Titanic script).
- Fetch the Page: We use the ‘requests’ library to download the website’s content and store it.
- Make it Readable: We take that raw website data and turn it into something we can easily work with using Beautiful Soup and the ‘lxml’ parser. This is our ‘soup’ object.
Preview (Optional): We can print out the ‘soup’ with .prettify() to get a nicely formatted look at the website’s structure. This is helpful for finding what we want to scrape.
Code Example:
Python
website = 'https://subslikescript.com/movie/Titanic-120338'
result = requests.get(website)
content = result.text
soup = BeautifulSoup(content, 'lxml')
print(soup.prettify())Next Up: Now that we have the ‘soup’, we’ll learn how to target the specific parts of the transcript we want to extract!
Check the Web Page and HTML Code
Before diving into code, it’s time for recon! Need to carefully examine the website’s structure, just like a detective chasing a target. Think of the HTML code as the building layout and the movie title and transcript as the valuables we locate.
Here’s the plan: We’ll analyze a sample transcript and its HTML to figure out the smartest way to tell our code exactly where to find the data we want.
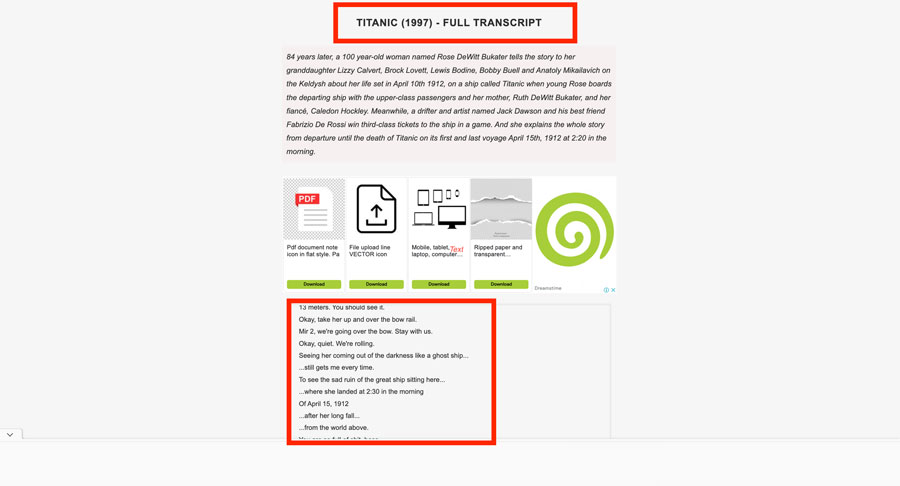
Want to peek behind the curtain of a website? Here’s how to reveal the HTML code for anything you see on the page:
- Go to the Titanic transcript website.
- Find either the movie title or a piece of the transcript you want to scrape. Right-click on it.
- Choose “Inspect” from the menu. This will open up your browser’s developer tools, showing you the website’s code!
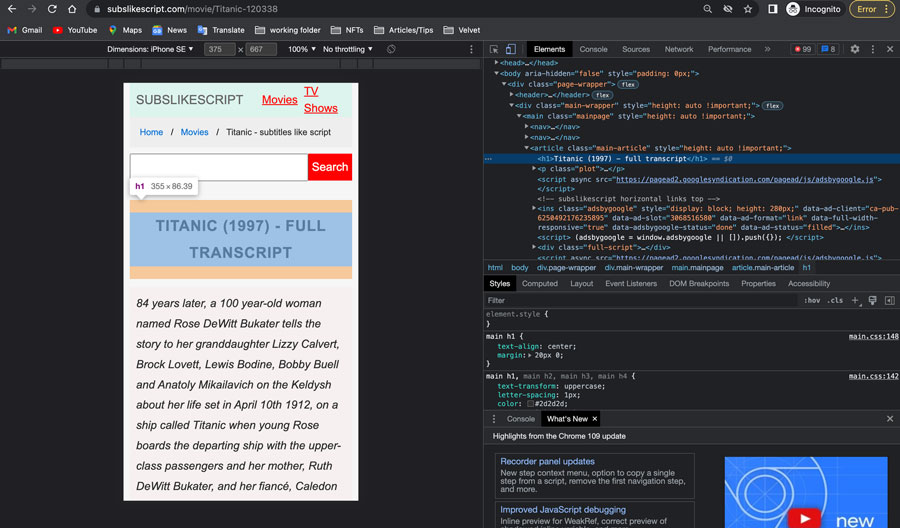
How to Seek an Element with Beautiful Soup?
Beautiful Soup provides a powerful toolset for effortlessly locating and extracting specific elements from web pages. Let’s explore how it works through the following example:
Objective: Identify and extract the title, description, and full script for a particular movie.
1. Pinpoint the Data Container: Employ the .find() method of Beautiful Soup to identify the HTML element encapsulating the desired information. In this instance, the article tag with the class main-article holds the movie information container.
box = soup.find('article', class_='main-article')2. Uncover the Movie Title: The movie title typically resides within an h1 tag inside the data container. Utilize the .find() method to locate the h1 tag and the .get_text() function to extract the title text.
title = box.find('h1').get_text()3. Get the Movie Script: The movie script is often enclosed within a div tag with the class full-script. Use the .find() method to identify the div tag and the .get_text() function to extract the script text.
script = box.find('div', class_='full-script')However, to ensure accurate script display, we modify the default arguments of the .get_text() function:
- strip=True: Eliminates extra whitespace at the beginning and end of each line.
- separator=’ ‘: Adds a space after each newline to guarantee proper text formatting.
script = script.get_text(strip=True, separator=' ')4. Check the Results: Print the title and script variables to confirm successful data extraction.
print(title)
print(script)With Beautiful Soup, you can easily search and scrape data from websites, turning discrete information into valuable data sets for your research, analysis or creative purposes.
How to Export Data into a .txt File?
Once you’ve successfully extracted valuable data from web pages using Beautiful Soup, it’s crucial to store it for future use. Beautiful Soup offers flexibility in saving data in various formats, including CSV, JSON, and plain text files.
In this example, we’ll save the extracted data to a text file named a.txt.
with open(f'{title}.txt', 'w') as file:
file.write(script)Explanation:
with open(…) as file: This context manager ensures the file is properly opened, written to, and closed, even if exceptions occur.
f'{title}.txt’, ‘w’: This part specifies the filename and opening mode.
f'{title}.txt’: Utilizes a formatted string to dynamically generate the filename based on the title variable.
‘w’: Indicates write mode, meaning the file will be overwritten if it already exists.
file.write(script): This line writes the extracted movie script (script) into the open file.
Additional Considerations:
- CSV (Comma-Separated Values): For structured data, CSV files are a popular choice due to their simplicity and compatibility with various tools.
- JSON (JavaScript Object Notation): JSON is ideal for storing structured data in a hierarchical and human-readable format. Other Formats: Depending on your specific needs, you can explore other formats like XML or custom data structures.
How to Scrape Multiple Web Pages?
To successfully scrape multiple movie scripts, we need to identify the page containing all the script links. Follow these steps:
1. Visit the website and search for the movie script
Open the website https://subslikescript.com/.
Scroll down the page and click “All Screenplays”. You can find this link at the bottom of the website.
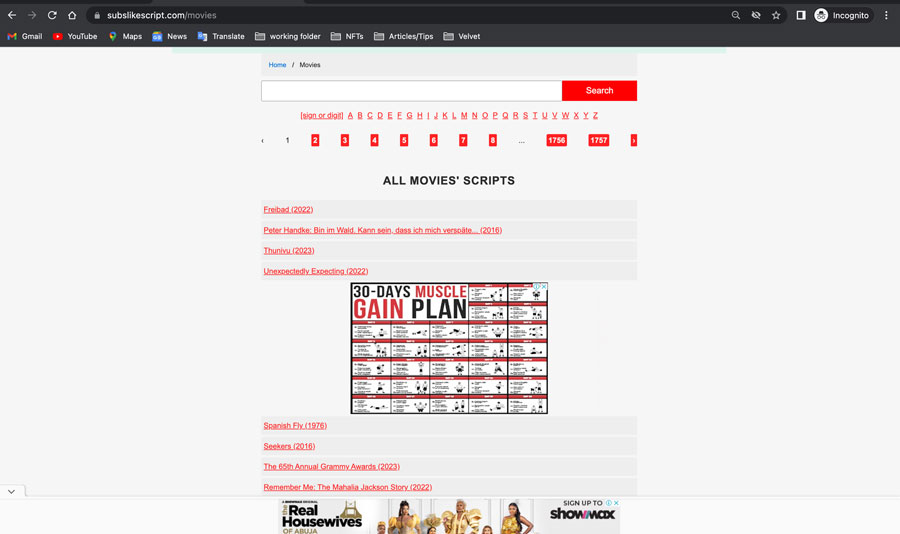
The website will display a list of all available screenplays. Each page displays about 30 screenplays, and there are 1,757 pages in total.
2. Remove unnecessary links
To effectively retrieve movie script data, remove irrelevant links from the website.
- Use a web scraping tool like Scrapy to scrape data from the website.
- In the Scrapy code, we define the root variable as the root URL of the website (https://subslikescript.com) and the url variable as the URL of the page containing the movie script list (https://subslikescript.com/movies).
- Use the root variable to remove the root URL portion from links leading to specific movie script pages.
Defining the root variable in the code simplifies the process of removing the root URL from the links in the next steps. Instead of manipulating the full URL directly, we just need to use the root variable to remove the root URL part easily.
Note:
- The process of retrieving screenplay data can be complex and requires knowledge of programming and web scraping tools.
- Use of collected data is subject to the website’s terms of service [invalid URL removed].
How to Extract the Href Attribute?
Let’s take a closer look at how those movie titles are structured in the HTML:
Inspect a Title: Right-click on any movie title in the “List of Movie Transcripts” and choose “Inspect”. You should see an ‘<a>’ tag highlighted in blue – this is the link!
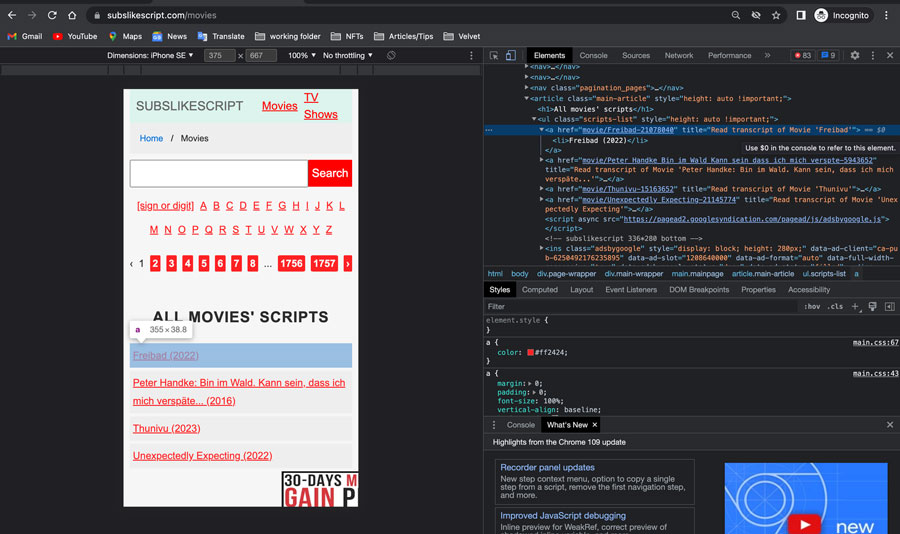
Partial Links: Notice that the links inside the ‘href’ attribute are missing the beginning part of the address (the domain, ‘subslikescript.com’). That’s why we made the ‘root’ variable earlier!
Grabbing All Links Our next step is to tell Beautiful Soup to find all those ‘<a>’ tags on the page. This will give us the building blocks to create the full addresses for each movie transcript.
How to Seek Multiple Elements?
To grab a bunch of elements at once, we use .find_all(). Since we specifically want links, we’ll tell it to look for ‘<a>’ tags that have the ‘href’ attribute set.
The good stuff (the actual link address) is stored in the ‘href’ attribute. Let’s loop through our results and grab those:
for link in box.find_all('a', href=True):
print(link['href']) # Check if we got the right linksList comprehension is a Python shortcut to make this code even tidier:
links = [link['href'] for link in box.find_all('a', href=True)]
print(links)Now, when you print the ‘links’ list, you should see all the movie transcript links ready for us to scrape!
How to Iterate Over each Link?
To conquer our mountain of movie transcripts, we’ll use a handy tool called a ‘for’ loop. Here’s how it works:
for link in links: # For each link in our list...
result = requests.get(f'{root}/{link}') # Fetch the transcript page
content = result.text
soup = BeautifulSoup(content, 'lxml') # Make it into a 'soup' objectWe build the full transcript URL by combining our ‘root’ variable with the individual ‘link’. This ensures we’re grabbing the right pages.
The code inside the loop is exactly what we did earlier to scrape a single page. Now, it’ll automatically repeat for every link we find!
Wow, you’ve learned a ton! This article gives you all the information about Web Scrape Multiple Pages. You now know how to tackle multiple pages and extract the data you need. That’s a major web scraping milestone!
If you have any questions along the way, or just want to talk about cool web scraping projects, don’t hesitate to reach out. I’m here to help!
Read more:






