Scrape Website to PDF emerges as a powerful solution, allowing you to extract website content and transform it into a universally accessible format – the Portable Document Format (PDF). This method empowers you to create static snapshots of website content, ensuring offline access and consistent presentation across various devices.
Imagine being able to easily archive essential information from a website, such as research articles, product manuals, or financial reports, all readily available in a single, organized PDF document. Scrape Website into PDF makes this a reality.
This guide delves into the world of web scraping for PDFs, exploring various techniques, their advantages and limitations, and ultimately equipping you with the knowledge to effectively extract website content and convert it into a versatile PDF format.
Whether you’re a researcher, a business professional, or simply someone who wants to preserve valuable online information, Scrape Website to PDF offers a practical and efficient solution.
What Is Web Scraping?
Web scraping is the process of using bots to crawl through web pages and retrieve information from them. This can involve text, images, tables, or any other content displayed on a webpage. Special tools or scripts are used to automate the process of collecting and organizing this data. Web scraping can be used for various purposes, such as:
- Market research: Gathering competitor pricing or product information.
- Data analysis: Collecting financial data or news articles for analysis.
- Lead generation: Extracting contact information from business directories.
- Monitoring changes: Tracking product availability or price fluctuations on e-commerce websites.
What Are PDF Scrapers?
PDF scrapers are specialized tools or techniques used to scrape website for PDFs and convert them into PDF files. They work by fetching the desired website content and formatting it into a structured PDF document, preserving the layout and essential elements of the webpage. There are three main categories of PDF scraper tools that you can use to scrape website to PDF:
- No-code Scrapers: These user-friendly platforms offer a visual interface, allowing users with no programming experience to point-and-click their way to extracting website content and generating PDFs.
- Python Scripting: For those with some coding knowledge, Python offers libraries like BeautifulSoup and Selenium to build custom scripts that scrape website content and convert it to PDF using external libraries like ReportLab.
- Browser Extensions: Some browser extensions provide basic scraping functionalities, allowing users to capture specific website sections and convert them to PDFs directly within the browser.
How to convert an entire website to PDF using RPA CLOUD?
RPA CLOUD simplifies work with its ultra-user-friendly interface. This powerful cloud-based software robot goes beyond automating repetitive tasks by offering robust web scraping services tailored for businesses of all sizes.
Whether it’s basic scanning or advanced plan upgrades, here’s what RPA CLOUD delivers:
Key Features:
- CSS Selection: Effortlessly obtain the inner text or HTML of elements matching CSS selectors.
- Complex Table Extraction: Seamlessly extract data from even the most intricate website tables.
- Information Processing: Streamline your data handling.
Step 1: Login to your account
First of all, to Scrape website to PDF you need to have an RPA account. Click here
Process:
1. Select a [Project] name. If you don’t have a project, click the ➕ button on the right to create a new one.
2. Enter robot name.
3. Choose whether to enable email notifications when the robot has an error.
Enter a description [if want] of the robot.
4. Finally, click the [OK] button to complete.
Step 2: Open the target browser
You need to choose a target browser for Scrape website to PDF.
Process:
1. Create action [Open browser].
2. Drag and drop the [Open Browser] action card.
3. Save
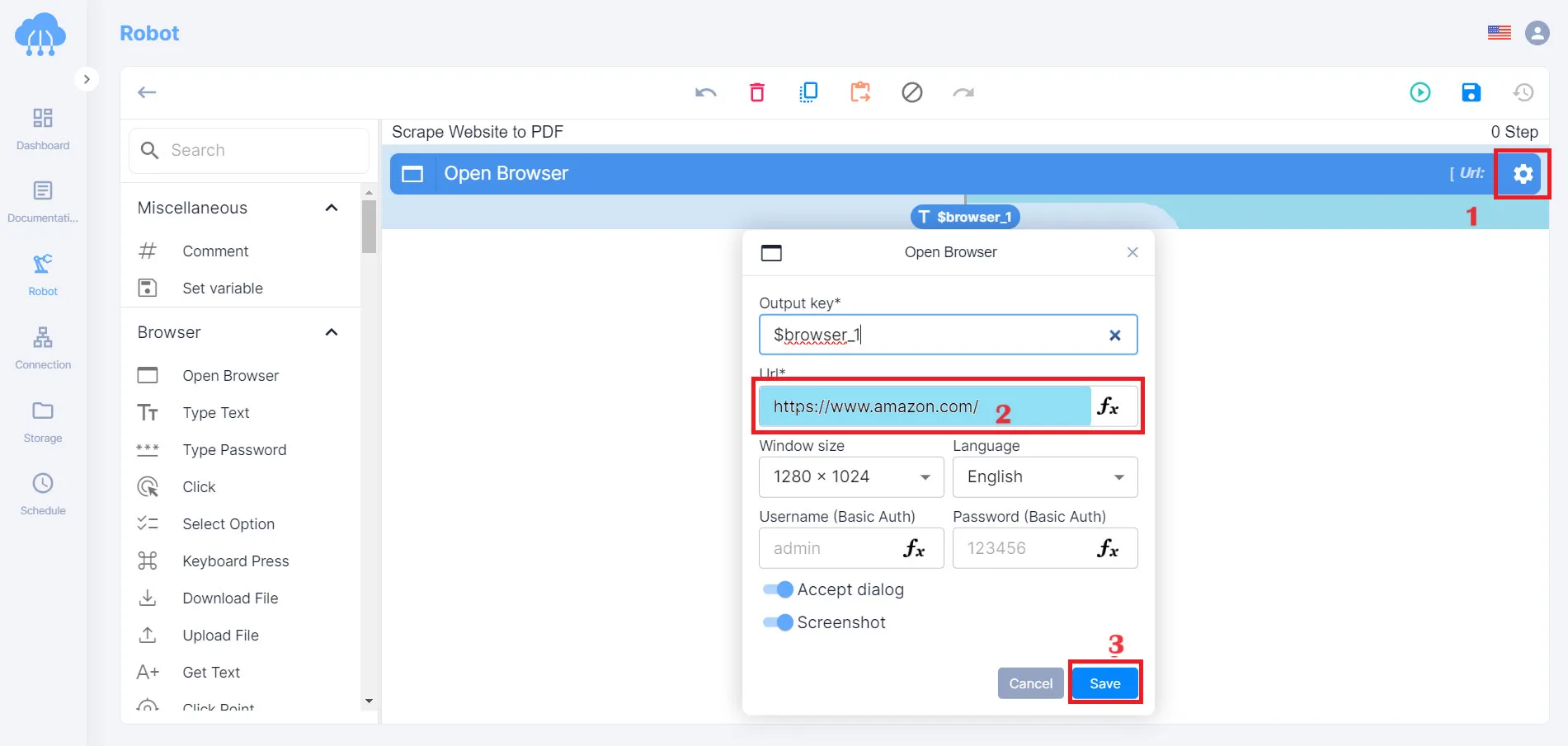
For example, if your target browser is Amazon.com
You type: amazon.com on Url
Finally, save the program
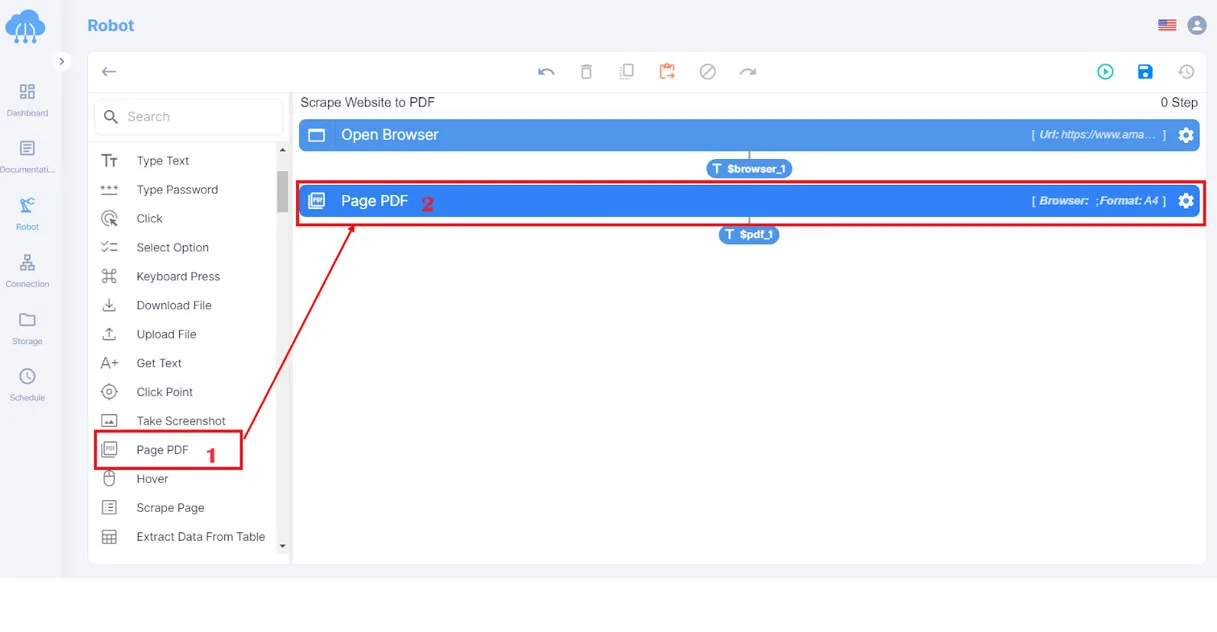
Step 3: Scrape Website to PDF
1. Create action [ Scrape Website to PDF].
2. Drag and drop the [Scrape Website to PDF] action card.
3. Save program
Format: you can choose size: A3, A4, A5
Page ranges: Depending on the number of pages you want to extract data
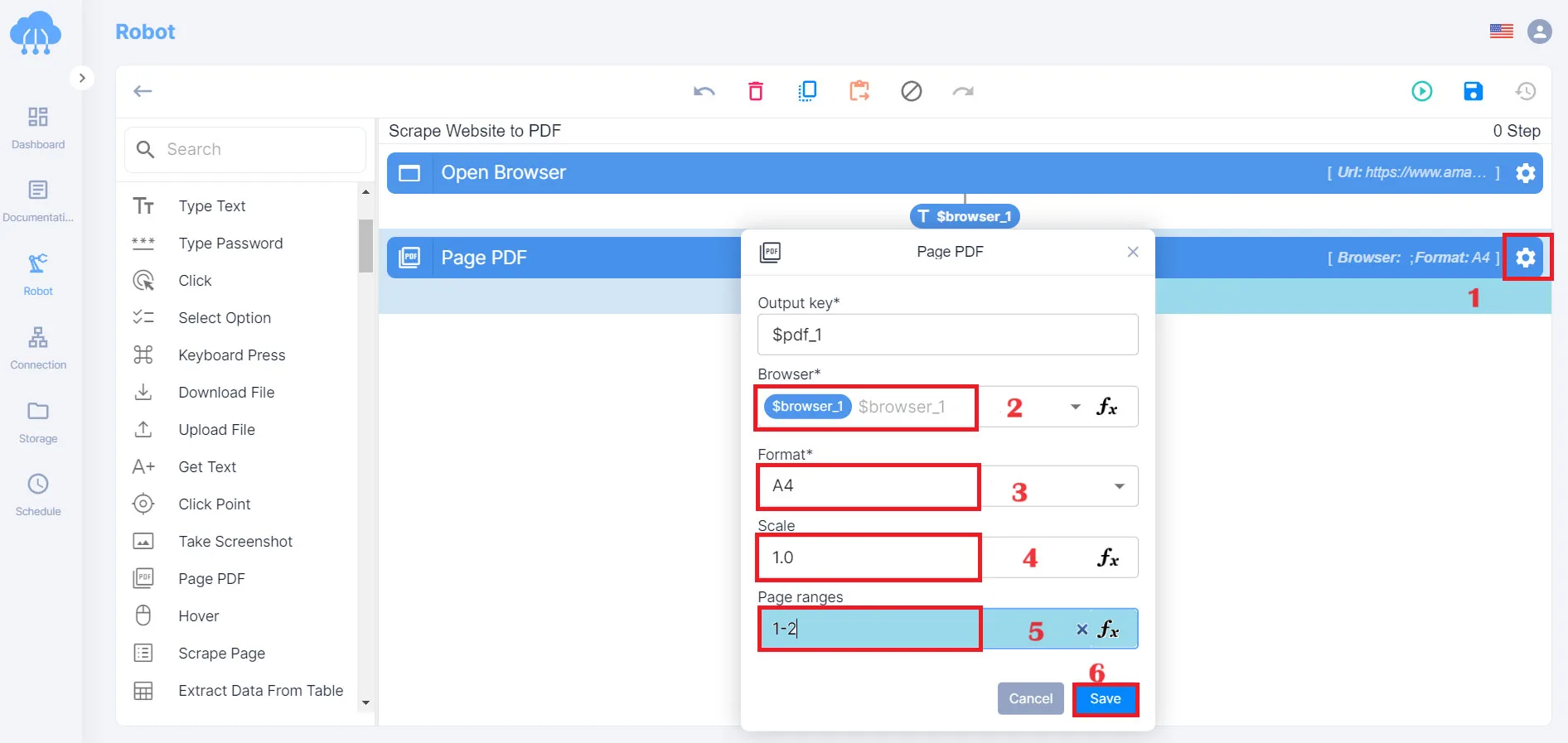
Click Save program when setup is complete.
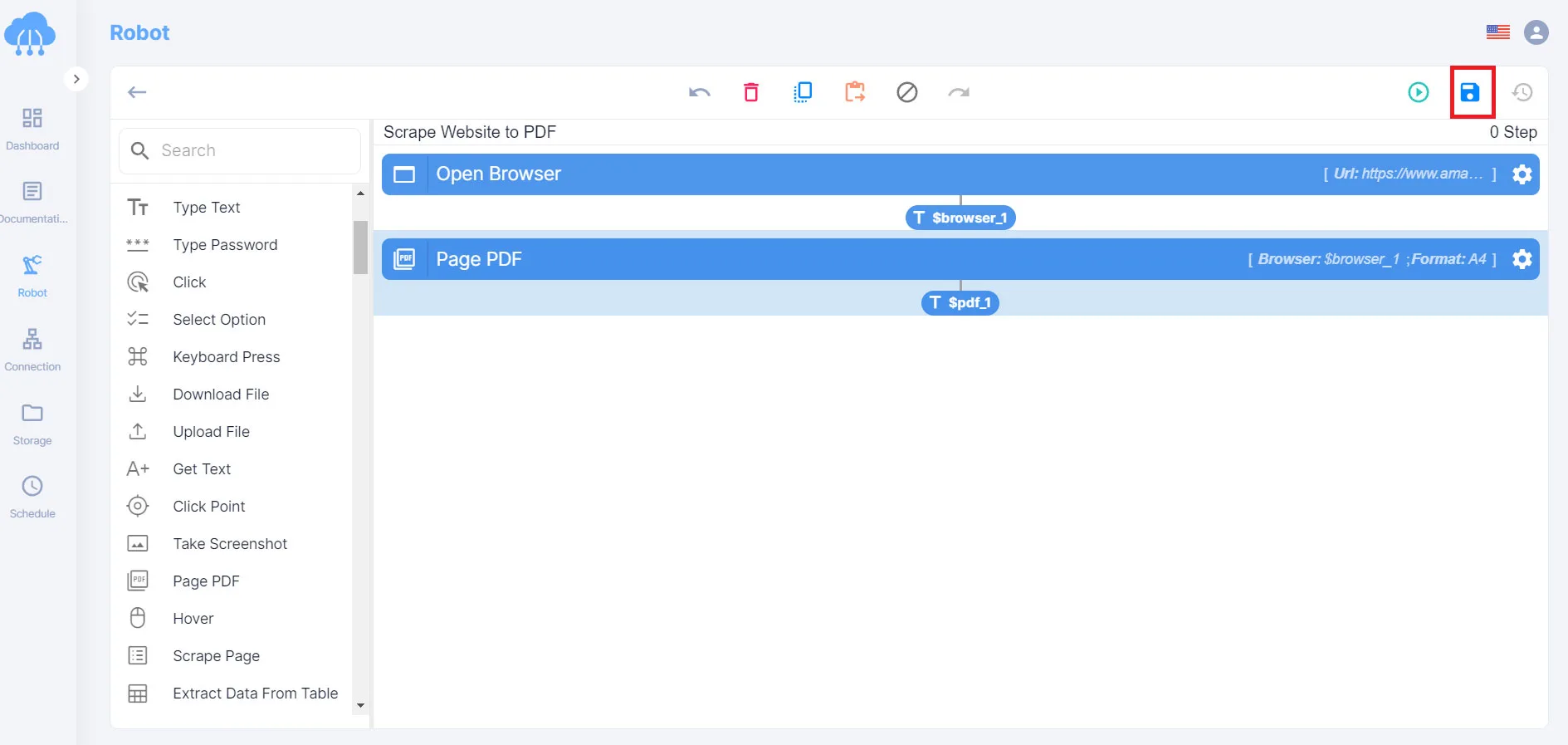
Step 4: Run the robot to test
You can test whether the script is well-implemented by running the script.
Process:
1. Click the [Run] button to run the script.
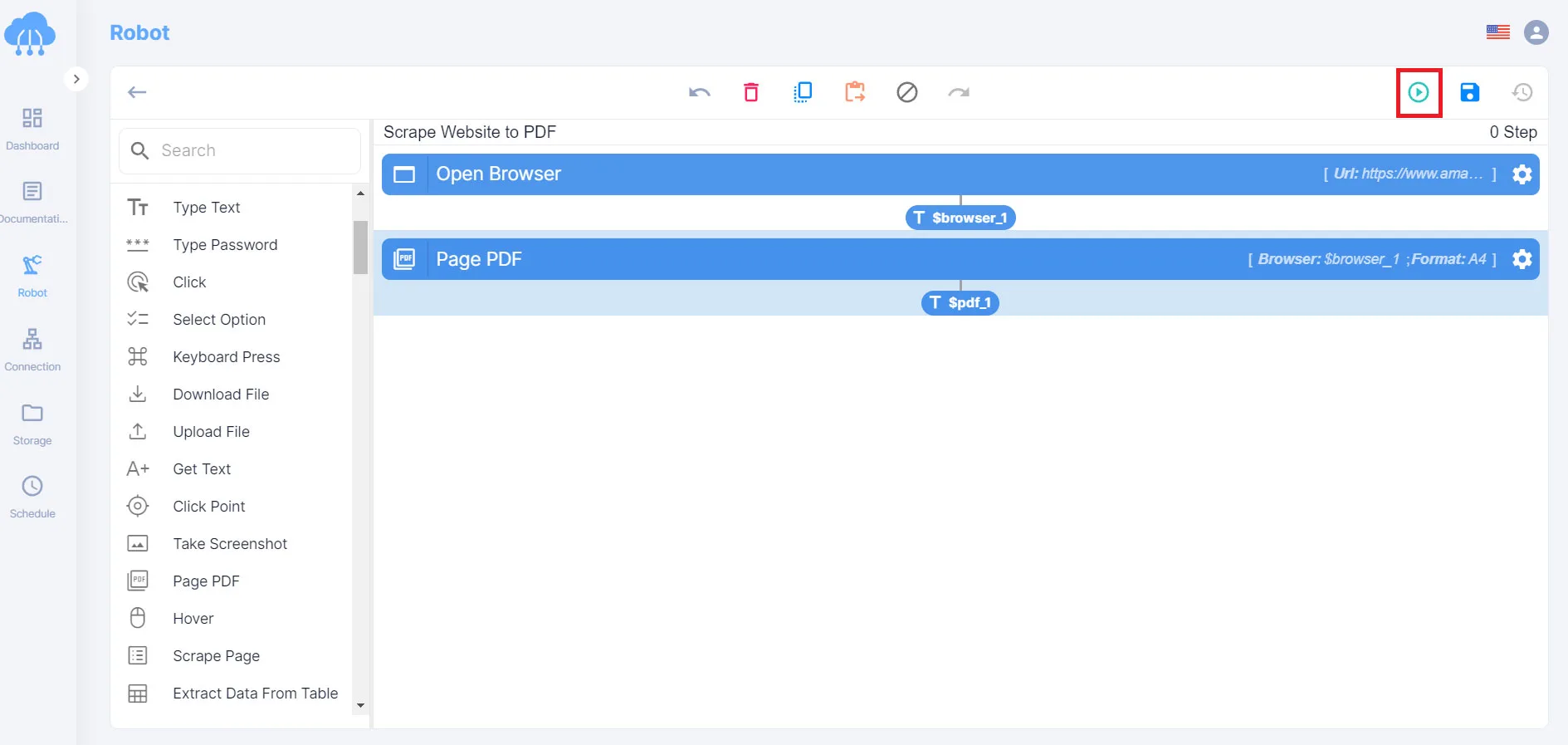
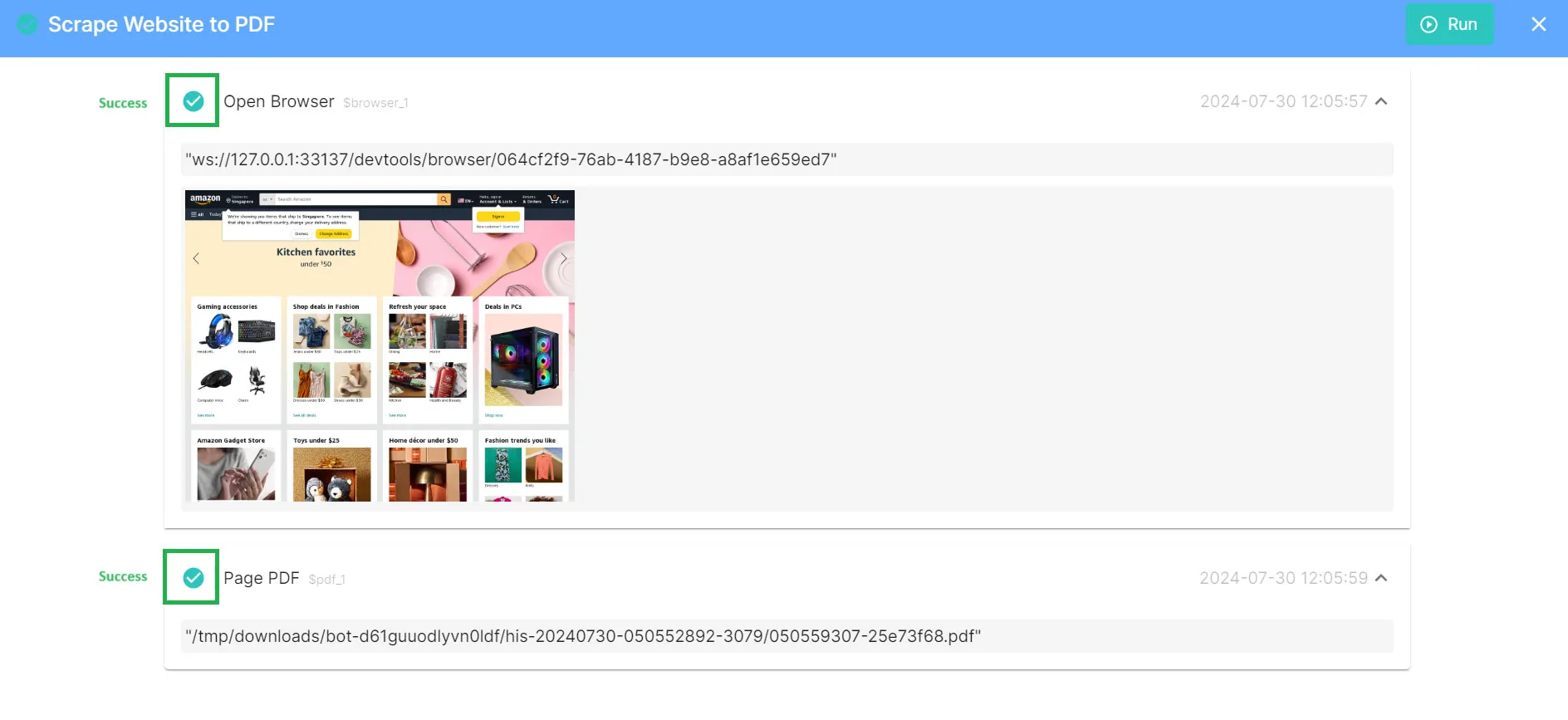
2. Check the returned results.
For operations performed on the browser, the results will be accompanied by an image if you select [Screenshot].
3. To return to the script editing screen click the ✖️ icon in the upper right.
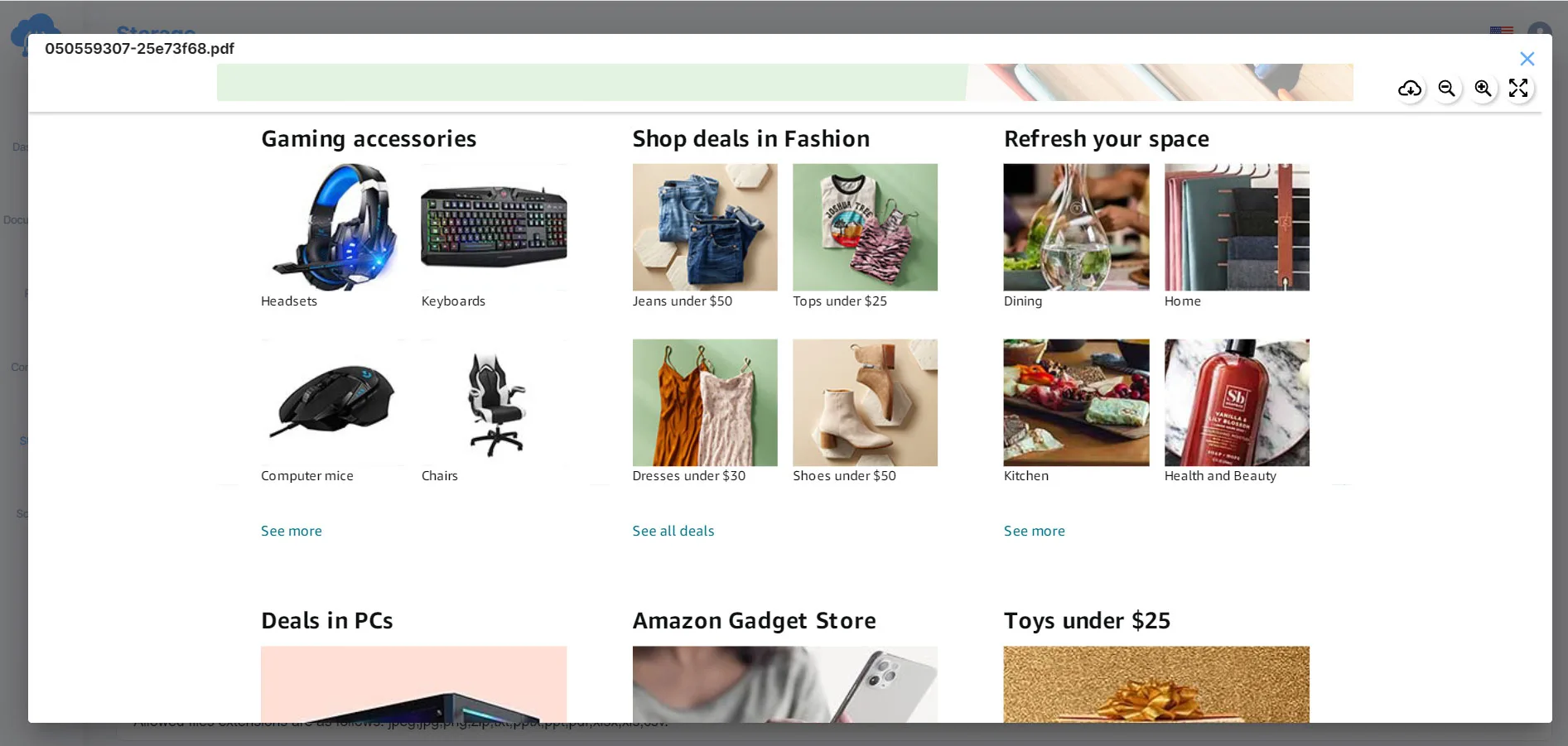
Step 5: Check and download the file
After the program ends, return to the Storage tab to check files and download files.
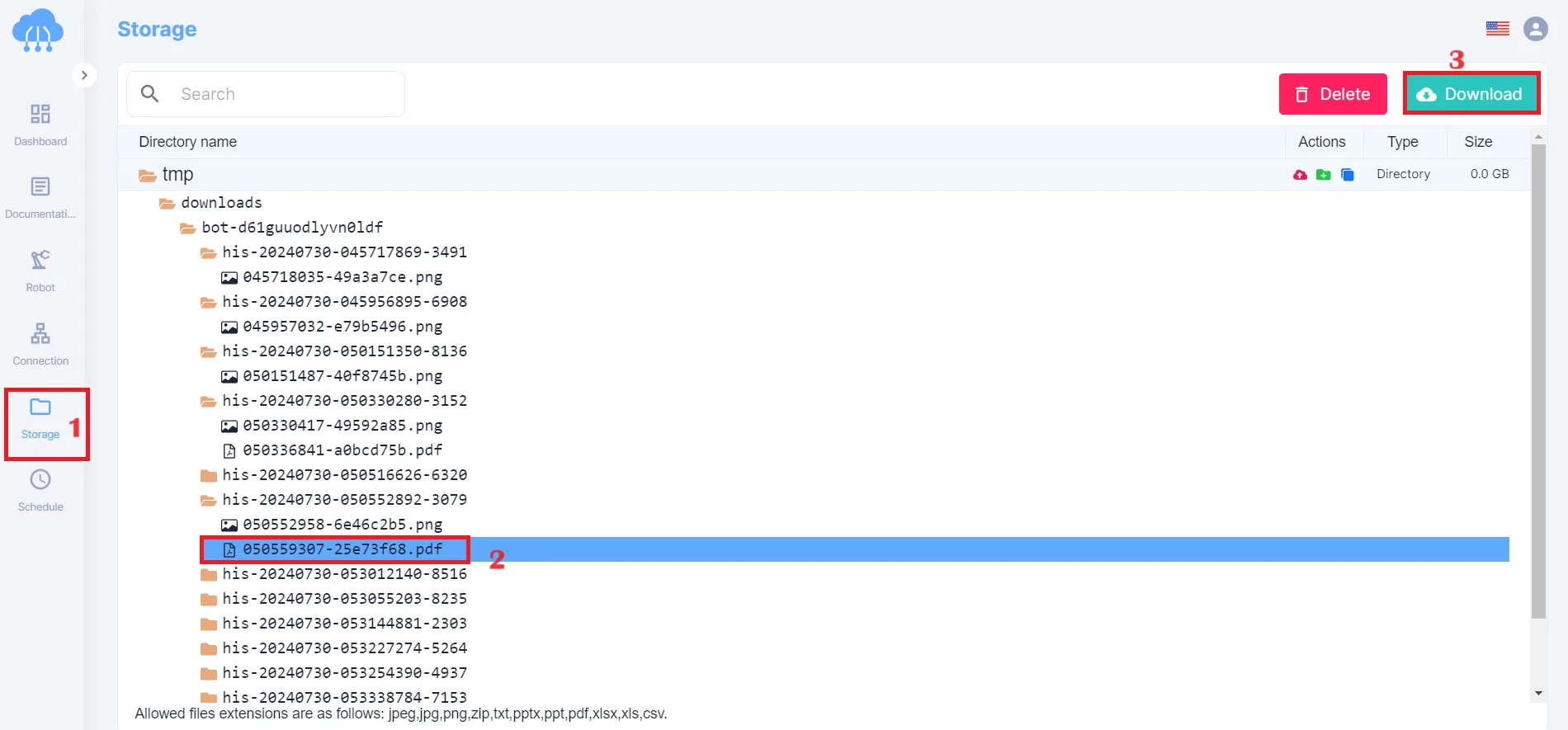
You can now view the extracted data in PDF format.
Scrape Website to PDF by No-code Scrapers?
No-code scraping tools are an excellent option for beginners or those who prefer a visual interface to scrape website to PDF. These platforms offer intuitive workflows and pre-built templates, allowing users to configure how data is extracted and displayed in the generated PDF. Popular no-code scraper options for PDF creation include:
ParseHub: This user-friendly platform walks you through the scraping process with a point-and-click interface. You can define the website content you want to capture and customize the layout of the generated PDF with various formatting options.
Web Scraper: This tool allows you to visually select the elements you want to extract from a website and convert them into a well-structured PDF. It offers basic data manipulation options within the generated PDF as well.
Octoparse: While primarily focused on data extraction, Octoparse offers the ability to export scraped data into a PDF format. It allows you to configure headers, footers, and basic page formatting for the generated PDF.
Benefits of Using No-code Scrapers
- User-friendly interface: No coding knowledge is required.
- Visual configuration: Point-and-click approach for defining content extraction.
- Pre-built templates: Streamlined setup for common scraping tasks.
- PDF generation: Built-in functionality to convert extracted data to PDF.
Drawbacks of Using No-code Scrapers
- Limited customization: This may offer less flexibility compared to coding methods.
- Free plans may have restrictions: Data extraction quotas or limited features.
- Complex websites: You may struggle with highly dynamic or JavaScript-heavy sites.
How to Scrape Website to PDF by Python?
Now, let’s dive into downloading files from a web directory! We’ll be utilizing two powerful Python libraries: Beautiful Soup, often considered the champion of web scraping tasks, and Requests for streamlined HTTP communication. As always, we’ll kick things off by installing the necessary packages.
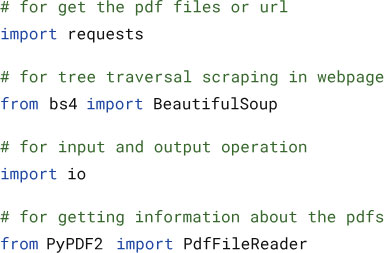
Next, we’ll use a Python library called Beautiful Soup to create a “parser.” This parser acts like a special tool that can read and understand the website’s code (HTML) and identify the files available for download.

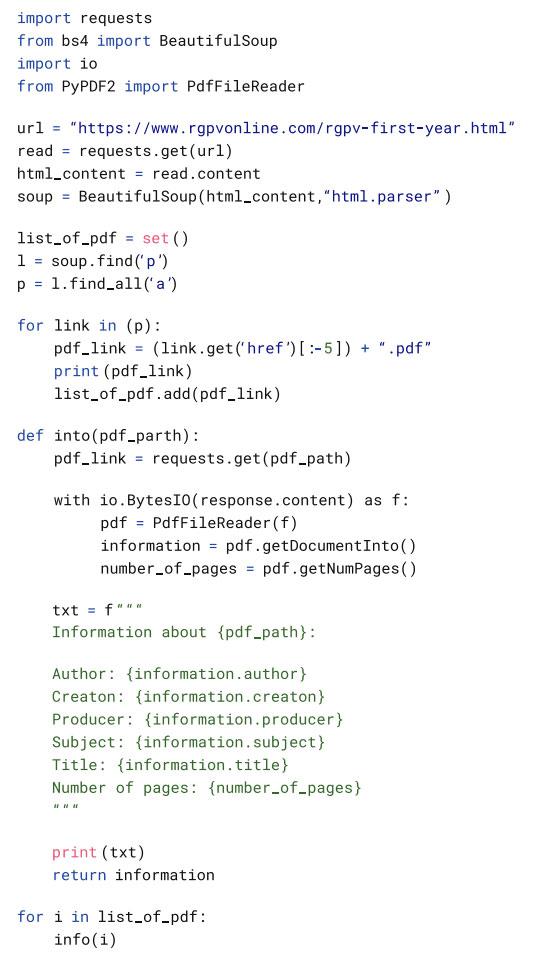
The next step involves processing the downloaded PDFs. We’ll need to iterate through them, likely using a loop, to identify the specific PDFs you’re interested in. To extract information from these PDFs, we’ll leverage the pypdf2 module. This module allows us to create an “info function” that can parse the PDF structure and extract the desired data. The complete code for this process will be shown next.
What Is Python PDF Scraping?
Python is a popular general-purpose programming language known for its readability and ease of use. It offers a vast ecosystem of libraries specifically designed for web scraping and PDF generation.
Therefore, Python PDF scraping refers to the process of using Python libraries and scripts to scrape data from a website and convert it into a PDF document.
Benefits of Using Python
Customization: Python offers a high level of customization compared to no-code scrapers or browser extensions. You can tailor the scraping process and PDF generation to meet your specific needs.
Flexibility: Python can handle complex websites with dynamic content or login requirements that might pose challenges for simpler scraping methods.
Open-source Libraries: A wide range of free and well-documented libraries are available for web scraping and PDF generation in Python, making it a cost-effective solution.
Limitations of Using Python
Coding Knowledge Required: A basic understanding of Python programming is necessary to write scraping scripts and utilize the libraries effectively.
Learning Curve: There’s a steeper learning curve compared to no-code solutions. You’ll need to invest time in learning Python and the relevant libraries.
Maintenance Effort: Your scraping scripts might require updates if the target website undergoes significant changes.
Common Python Libraries to Scrape Website to PDF
Essential Python Libraries for PDF Scraping:
- PDFMiner: This popular tool excels at extracting text content from PDF documents. It’s ideal for tasks like summarizing text or analyzing written information within PDFs.
- PyPDF2: A versatile library for manipulating PDF files. It allows you to extract content, split PDFs into separate pages, merge documents, crop-specific areas, and even transform page layouts. It works with both encrypted and unencrypted PDFs.
- Tabula-py: This library specializes in processing tables embedded within PDF documents. It can convert these tables into a structured format like a pandas DataFrame, making data analysis and manipulation a breeze. Additionally, Tabula-py lets you export the extracted tables into CSV or JSON files for further use.
- PDFQuery: If you’re looking for a concise approach to PDF data extraction, PDFQuery might be your champion. This library utilizes a CSS-like syntax, allowing you to pinpoint specific data elements within the PDF structure with minimal code.
How to Scrape Website to PDF by Browser Extensions
Browser extensions offer a simple approach to scrape website to PDF. Several extensions cater to website content capture, allowing users to select specific areas on a web page and convert them into a PDF file.
Popular browser extensions for scraping to PDF include:
FireShot: Available for Chrome, Firefox, and other browsers, FireShot allows users to capture entire webpages, specific areas, or visible portions as PDFs.
Web Clipper: This Chrome extension allows capturing webpages as full PDFs, article-only PDFs, or bookmarks. It offers basic annotation features within the generated PDF.
Scrapy: While primarily a web scraping framework, Scrapy offers browser extensions like “Splash” that can render dynamic content and convert the webpage to a PDF.
Benefits
- Easy to use: Simple click-and-convert functionality.
- No coding required: Ideal for users with no programming experience.
- Wide availability: Many free and paid extensions are available for various browsers.
Drawbacks
- Limited customization: Offers minimal control over content selection or PDF formatting.
- Basic functionality: This may not handle complex website structures or login requirements.
Why Scrape Website to PDF?
Scraping websites and converting the content into PDFs offers several compelling advantages. Firstly, PDFs provide offline access, allowing you to read and reference the website content even without an internet connection.
Secondly, PDFs are a standardized format, ensuring consistent presentation across various devices with compatible PDF readers. This makes them ideal for sharing or archiving website content in a reliable format.
Furthermore, scraping allows you to extract specific website sections and organize them within a single PDF for easier analysis or reference. This can be particularly useful if you only need a specific portion of the website information.
Is It Legal to Convert Website Data to PDF and download?
The legality of scraping websites and converting content to PDF depends on several factors:
Website terms of service: Always check the website’s terms of service (TOS) or robots.txt file to see if they explicitly prohibit scraping. Respecting robots.txt guidelines is generally considered good practice.
Data usage: Ensure your scraping activities and use of the extracted data comply with copyright laws and fair use principles. Avoid scraping content for commercial purposes without permission if it is copyrighted by the website owner.
Respecting robots.txt: Robots.txt files provide instructions for automated bots (including scrapers) on how to interact with a website. Following these guidelines demonstrates responsible scraping practices.
It’s important to approach website scraping ethically and responsibly. Always prioritize respecting website terms of service and copyright laws when scraping content and converting it to PDFs.
FAQs: Scrape Website To PDF
How to Scrape Website for PDFs?
Besides scraping data manually, there are many other ways to make this job faster and more convenient. The method you choose depends on your technical expertise and scraping needs. Here’s a quick breakdown:
No-code scraper: Ideal for beginners, offering a user-friendly interface to configure scraping and PDF generation.
Python scripting: For advanced users, Python offers powerful libraries for customizing the scraping process and PDF output.
Browser extensions: Simple solution for basic scraping needs, allowing capture of specific web page sections as PDFs.
How to Use Python to Scrape and Download PDFs from a Website?
To get started, we’ll need two essential Python libraries: Beautiful Soup and PdfReader. Beautiful Soup acts like a web page detective, helping us examine website URLs and understand their structure (HTML). This allows us to locate the files we want to download.
Once we’ve downloaded the files, PdfReader comes into play. This library helps us handle and potentially save the downloaded files in the desired format.
Scrape Website to PDF empowers you to transform online content into a portable and accessible format, unlocking a wealth of possibilities. This guide has equipped you with a comprehensive understanding of various scraping techniques, from user-friendly no-code tools to the power and flexibility of Python scripting. You’ve also explored the advantages of scraping websites for PDF creation, including offline access, standardized formatting, and efficient data organization.
Remember, responsible scraping practices are crucial. Always respect website terms of service and copyright laws when extracting content. With the knowledge gained from this guide, you can now make informed decisions about the best approach for your Scrape Website To PDF needs.
So, leverage the power of this technique to capture valuable online information, streamline your workflow, and ensure you always have access to the content you need, converted into a convenient and universally accessible PDF format.
Read more:






